Modelado / Modelling
Un modelo es una representación simplificada de la realidad creada para un propósito concreto. Las hipótesis que asumimos, la selección de características relevantes, las restricciones y la trazabilidad de cómo se construye forman parte de ese modelo.
Un ejemplo clásico es un mapa: una representación cartográfica que permite situar lugares de interés, calcular distancias o analizar relaciones topológicas entre puntos.
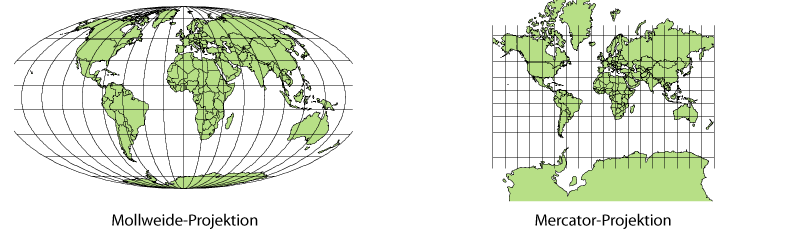
Fuente imagen: Wikipedia
En ciencia de datos distinguimos, de forma general:
Modelos predictivos: conjuntos de fórmulas o reglas que permiten estimar valores desconocidos (por ejemplo, predecir ventas futuras).
Modelos descriptivos: ayudan a descubrir patrones subyacentes o estructura en los datos (por ejemplo, segmentos de clientes).
Los datos usados por el modelo representan hechos u observaciones de la realidad (o de otro modelo). Siguiendo el ejemplo del mapa, serían los puntos, contornos o bordes del territorio representado.
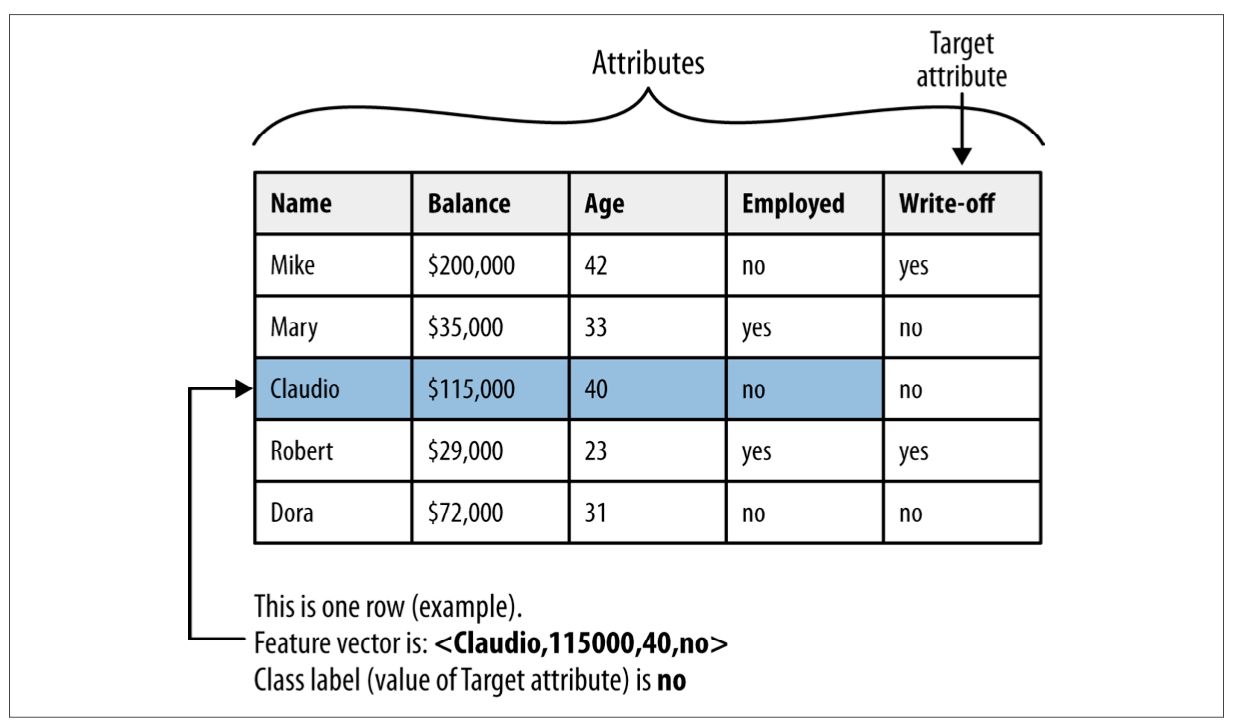
Fuente de ambas figuras [2]
El proceso de aprendizaje automático
Podemos esquematizar el proceso de aprendizaje automático en varias etapas:
- Preparación de datosCarga, limpieza, transformación y división del conjunto de datos.
Incluye el análisis exploratorio de datos (EDA) y la selección de características.
- Selección de la técnicaElección del tipo de tarea (clasificación, regresión, clustering…), de los modelos candidatos y de las restricciones prácticas (tiempo, interpretabilidad, recursos, etc.).
- Ajuste de hiperparámetrosLos hiperparámetros son configuraciones del modelo que no se aprenden directamente de los datos (por ejemplo, profundidad máxima de un árbol) y deben ajustarse manualmente o mediante búsqueda automática.
- Evaluación del modeloPruebas iniciales, elección de métricas, ajustes iterativos y evaluación final sobre datos no vistos.
Selección de atributos o métricas adecuadas
Dado un conjunto de muestras con muchas características, el reto es elegir aquellas que realmente contribuyen al aprendizaje del modelo.
Supongamos el siguiente ejemplo de personas: 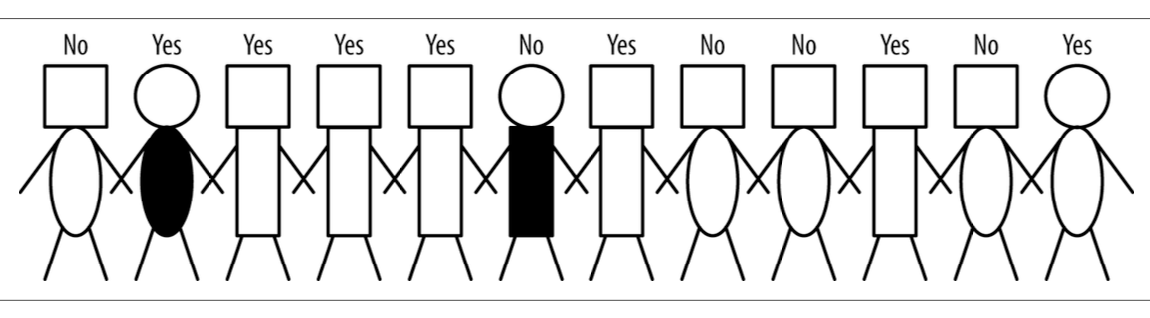
Las características disponibles son:
Forma de la cabeza: cuadrada o circular.
Forma del cuerpo: rectangular o ovalada.
Color del cuerpo: negro o blanco.
Función de su compra: yes/no.
Esta última característica es el atributo objetivo (target): lo que queremos predecir en futuros clientes.
Para predecirlo, debemos preguntarnos qué atributos aportan información útil. Si solo usáramos, por ejemplo, el color del cuerpo, podríamos perder variabilidad importante del resto de la población y construir un modelo pobre.
Más adelante retomaremos este problema de selección de atributos introduciendo los conceptos de entropía y ganancia de información.
Nuestra primera aplicación de machine learning (ML)
### Instalación de librerías
La librería de Python que implementa múltiples algoritmos de ML es scikit-learn
Scikit-learn: https://scikit-learn.org/stable/
Trabajemos con las versiones de librerías usadas en Google Colab (09/12/25) como sistema de referencia.
Podemos usar UV:
[113]:
!uv init
Adding `07-machinelearning` as member of workspace `/Users/isaac/Projects/Subjects/TTAD_master`
Initialized project `07-machinelearning`
[114]:
!uv add scikit-learn==1.6.1
!uv add sklearn-pandas==2.2.0
!uv add seaborn==0.13.2
Resolved 100 packages in 280ms
Audited 5 packages in 0.31ms
Resolved 100 packages in 18ms
Audited 11 packages in 0.04ms
Resolved 100 packages in 14ms
Audited 20 packages in 0.05ms
Y si tuvieramos pip:
!pip install scikit-learn==1.6.1
!pip install sklearn-pandas==2.2.0
!pip install seaborn==0.13.2
Datos
Vamos a utilizar el siguiente catálogo de datos: Mushroom Data Set http://archive.ics.uci.edu/ml/datasets/Mushroom
Disponible en: “data/mushrooms.csv”
[115]:
import pandas as pd
import numpy as np
df = pd.read_csv("data/mushrooms.csv")
# Por simplicidad, renombramos las columnas
es_col = [
"clase",
"forma del sombrero",
"superficie del sombrero",
"color del sombrero",
"magulladuras",
"olor",
"unión de las láminas",
"espaciamiento de las láminas",
"tamaño de las láminas",
"color de las láminas",
"forma del tallo",
"raíz del tallo",
"superficie del tallo por encima del anillo",
"superficie del tallo por debajo del anillo",
"color del tallo por encima del anillo",
"color del tallo por debajo del anillo",
"tipo de velo",
"color del velo",
"número de anillos",
"tipo de anillo",
"color de la impresión de esporas",
"población",
"hábitat"
]
df.columns = es_col
print(df.shape)
print("-"*100)
print(df.columns)
print("-"*100)
print(df.head(3))
(8124, 23)
----------------------------------------------------------------------------------------------------
Index(['clase', 'forma del sombrero', 'superficie del sombrero',
'color del sombrero', 'magulladuras', 'olor', 'unión de las láminas',
'espaciamiento de las láminas', 'tamaño de las láminas',
'color de las láminas', 'forma del tallo', 'raíz del tallo',
'superficie del tallo por encima del anillo',
'superficie del tallo por debajo del anillo',
'color del tallo por encima del anillo',
'color del tallo por debajo del anillo', 'tipo de velo',
'color del velo', 'número de anillos', 'tipo de anillo',
'color de la impresión de esporas', 'población', 'hábitat'],
dtype='object')
----------------------------------------------------------------------------------------------------
clase forma del sombrero superficie del sombrero color del sombrero \
0 p x s n
1 e x s y
2 e b s w
magulladuras olor unión de las láminas espaciamiento de las láminas \
0 t p f c
1 t a f c
2 t l f c
tamaño de las láminas color de las láminas ... \
0 n k ...
1 b k ...
2 b n ...
superficie del tallo por debajo del anillo \
0 s
1 s
2 s
color del tallo por encima del anillo color del tallo por debajo del anillo \
0 w w
1 w w
2 w w
tipo de velo color del velo número de anillos tipo de anillo \
0 p w o p
1 p w o p
2 p w o p
color de la impresión de esporas población hábitat
0 k s u
1 n n g
2 n n m
[3 rows x 23 columns]
### Planteamiento del objetivo de ML
¿Cuál es el objetivo que planteamos? ¿Qué valos nos interesa encontrar?
En este caso, queremos determinar la población según las características del hongo
Esta variable contiene los siguientes datos:
population: abundant=a, clustered=c, numerous=n, scattered=s, several=v, solitary=y
[116]:
# Podemos ver los valores de la variable objetivo
print(df["población"].head())
value,counts = np.unique(df["población"], return_counts=True)
print(value,counts)
0 s
1 n
2 n
3 s
4 a
Name: población, dtype: object
['a' 'c' 'n' 's' 'v' 'y'] [ 384 340 400 1248 4040 1712]
¿Qué tipo de poblema de ML es?
Supervisado o No Supervisado?
Clasificación, Regresión o Agrupamiento?
Selección de características (feature selection)
En este primer problema, usaremos todas las muestras.
Tenemos que separar el dataset en dos partes: características y variable objetivo.
[117]:
df_y = df["población"].copy()
df_x = df.drop(labels=["población"],axis=1).copy()
print(df_x.shape)
print(df_y.shape)
(8124, 22)
(8124,)
Preparación de los datos de entreno (train) y datos de comprobación (test)
Podemos hacerlo de múltiples maneras, y es crítico en series temporales. Hay métodos automaticos que nos separan las muestras como por ejemplo: train_test_split
[118]:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_x,df_y, test_size=0.2, random_state = 0)
print("x_train:", x_train.shape)
print("y_train: ",y_train.shape)
print("-"*100)
print("x_test: ",x_test.shape)
print("y_test: ",y_test.shape)
x_train: (6499, 22)
y_train: (6499,)
----------------------------------------------------------------------------------------------------
x_test: (1625, 22)
y_test: (1625,)
Elección del algoritmo
Existen múltiples algoritmos según el tipo de problema de ML. En este ejemplo, usaremos ```Máquinas de Vectores de Soporte (SVM)’’’
[ ]:
from sklearn.svm import SVC
clf = SVC(C=1.0, kernel="linear", random_state=0) #¿Que implica el kernel?
#clf.fit(x_train, y_train) # Alerta: Genera un error!!! ¿Por qué?
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/var/folders/6j/7gfvt_29797dypw8t1wttblw0000gn/T/ipykernel_24248/3448651391.py in ?()
1 from sklearn.svm import SVC
2
3 clf = SVC(C=1.0, kernel="linear", random_state=0) #¿Que implica el kernel?
----> 4 clf.fit(x_train, y_train) # Alerta: Genera un error!!! ¿Por qué?
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)
1385 skip_parameter_validation=(
1386 prefer_skip_nested_validation or global_skip_validation
1387 )
1388 ):
-> 1389 return fit_method(estimator, *args, **kwargs)
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/svm/_base.py in ?(self, X, y, sample_weight)
193
194 if callable(self.kernel):
195 check_consistent_length(X, y)
196 else:
--> 197 X, y = validate_data(
198 self,
199 X,
200 y,
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/utils/validation.py in ?(_estimator, X, y, reset, validate_separately, skip_check_array, **check_params)
2957 if "estimator" not in check_y_params:
2958 check_y_params = {**default_check_params, **check_y_params}
2959 y = check_array(y, input_name="y", **check_y_params)
2960 else:
-> 2961 X, y = check_X_y(X, y, **check_params)
2962 out = X, y
2963
2964 if not no_val_X and check_params.get("ensure_2d", True):
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
1366 )
1367
1368 ensure_all_finite = _deprecate_force_all_finite(force_all_finite, ensure_all_finite)
1369
-> 1370 X = check_array(
1371 X,
1372 accept_sparse=accept_sparse,
1373 accept_large_sparse=accept_large_sparse,
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_all_finite, ensure_non_negative, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
1052 )
1053 array = xp.astype(array, dtype, copy=False)
1054 else:
1055 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
-> 1056 except ComplexWarning as complex_warning:
1057 raise ValueError(
1058 "Complex data not supported\n{}\n".format(array)
1059 ) from complex_warning
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
835 # Use NumPy API to support order
836 if copy is True:
837 array = numpy.array(array, order=order, dtype=dtype)
838 else:
--> 839 array = numpy.asarray(array, order=order, dtype=dtype)
840
841 # At this point array is a NumPy ndarray. We convert it to an array
842 # container that is consistent with the input's namespace.
~/Projects/Subjects/TTAD_master/.venv/lib/python3.12/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
2167 )
2168 values = self._values
2169 if copy is None:
2170 # Note: branch avoids `copy=None` for NumPy 1.x support
-> 2171 arr = np.asarray(values, dtype=dtype)
2172 else:
2173 arr = np.array(values, dtype=dtype, copy=copy)
2174
ValueError: could not convert string to float: 'e'
[ ]:
# El error proviene porque los SVM tan solo funcionan con variables continuas (números)
# Algunos algoritmos como los árboles de decisión, si funcionan con variables categoricas
# En nuestro caso, tenemos que transformar las variables categoricas a variables discretas
# Existen múltiples maneras de hacerlo. En este caso, usaremos el ```LabelEncoder```
# Basicamente, lo que hace es asignar un número a cada categoría. La gestión de esta asignación recae en este encoder.
# La opción más correcta es usar One-Hot Encoding (Anexo A), pero dada su dificultad lo haremos de esta manera.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # lo creamos
# Aplicamos el encoder a todas las columnas del dataset inicial!!!
for i in df.columns:
df[i] = le.fit_transform(df[i]) # lo aplicamos a cada columna,
print(df.iloc[:3,:3]) #imprimimos un par de filas y columnas para ver el resultado
# Por lo tanto, no nos quedará más remedio que crear de nuevo la partición del dataset con la variable objetivo y las características
x_train, x_test, y_train, y_test = train_test_split(df.drop('población', axis=1),df['población'], test_size=0.2,random_state=0)
clase forma del sombrero superficie del sombrero
0 1 5 2
1 0 5 2
2 0 0 2
[127]:
clf.fit(x_train, y_train) # Ahora sí! Entrenamos el modelo: TRAIN
[127]:
SVC(kernel='linear', random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(kernel='linear', random_state=0)
[128]:
# Una vez entrenado, podemos usar el modelo para predecir sobre nuevos datos o sobre los datos de control
y_pred = clf.predict(x_test) # predecimos sobre los valores reservados
[131]:
print(y_pred[0:5])
print(y_test[0:5])
[4 5 2 3 5]
380 3
3641 5
273 2
1029 0
684 4
Name: población, dtype: int64
Métricas
Los datos de comprobación o de test nos sirven para medir la bondad del algoritmo sobre valores objetivos que conocemos.
Las métricas dependerán del tipo de algoritmo. En este caso, estamos aplicando un algoritmo de clasificación, por lo tanto, tenemos métricas como la precisión, recall, f1-score, etc.
[ ]:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred)) #comprobamos el error
precision recall f1-score support
0 0.44 0.58 0.50 65
1 0.67 1.00 0.81 62
2 0.48 0.33 0.39 93
3 0.45 0.42 0.44 237
4 0.79 0.63 0.70 827
5 0.48 0.70 0.57 341
accuracy 0.61 1625
macro avg 0.55 0.61 0.57 1625
weighted avg 0.64 0.61 0.62 1625
Cuando se obtienen los valores, el problema continua: ¿Qué interpretación podemos hacer? ¿Es un buen método?…
Evaluación de un modelo de aprendizaje
La evaluación tiene como propósito validar el modelo y ganar confianza en su uso.
Podemos distinguir dos perspectivas:
- Cualitativa¿El modelo contribuye a los objetivos de negocio y a la toma de decisiones?¿Es integrable en los sistemas existentes?¿Encaja con el stack tecnológico y los requisitos legales/éticos?
- CuantitativaSe apoya en métricas: tanto de rendimiento computacional (tiempo, memoria, coste) como de desempeño del modelo (error, precisión, etc.).
Métricas
En clasificación
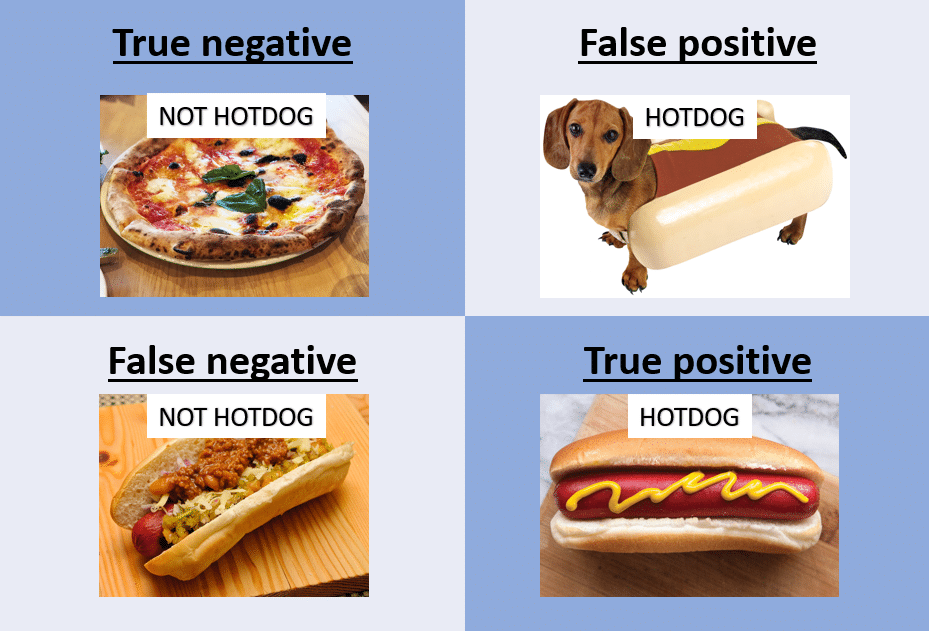
Source: NillsF blog
Accuracy: proporción de predicciones correctas sobre el total: $ \frac{TP+TN}{Total}.$
Precision: proporción de predicciones positivas que son realmente positivas: \(\frac{TP}{Results} = \frac{TP}{TP+FP}\)
Recall (sensibilidad): proporción de positivos reales correctamente identificados: \(\frac{TP}{Predictive Results} = \frac{TP}{TP+FN}\)
F1-score: media armónica de precisión y recall: \(\frac{2}{recall^{-1}+precision^{-1}}\)
- Área bajo la curva ROC (AUC): para clasificación binaria.La curva ROC compara la tasa de verdaderos positivos frente a la tasa de falsos positivos para distintos umbrales, y el AUC mide la capacidad del modelo para separar ambas clases.
- Matriz de confusión: tabla que cruza valores reales con valores predichos:\[\begin{split}\begin{equation} \begin{pmatrix} TP & FN \\ FP & TN \end{pmatrix} \end{equation}\end{split}\]
En regresión
Mean Absolute Error (MAE): media de las diferencias absolutas entre predicciones y valores reales.
Mean Squared Error (MSE): media de los cuadrados de las diferencias entre predicciones y valores reales (no es exactamente la desviación estándar, sino su cuadrado excepto por factores de normalización).
Coeficiente de determinación (R^2): indica qué proporción de la variabilidad de la variable objetivo explica el modelo.
(R^2) ajustado (Adjusted (R^2)): versión de (R^2) que penaliza la inclusión de variables adicionales y es más adecuada para comparar modelos con distinto número de predictores.
Muchas de estas métricas (y otras adicionales) están implementadas en la librería scikit-learn:
Nota: Iremos utilizando las principales métricas en las unidades siguientes.
Para el caso anterior, podemos calcular algunas de estas métricas de la siguiente manera:
[ ]:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
0.6123076923076923
[ ]:
from sklearn import metrics
metrics.precision_score(y_test,y_pred,average="weighted")
0.6413835956221657
[ ]:
print("Recall: ",metrics.recall_score(y_test,y_pred,average="weighted"))
print("F1_score: ",metrics.f1_score(y_test,y_pred,average="weighted"))
Recall: 0.6123076923076923
F1_score: 0.6153073145466426
Rendimiento computacional
Cada operación tiene un coste computacional: no solo tiempo de ejecución, sino también memoria para almacenar datos y valores intermedios.
La capacidad de CPU/GPU suele medirse en operaciones por segundo, por ejemplo:
MIPS (millones de instrucciones por segundo)
MFLOPS / GFLOPS (millones / miles de millones de operaciones en coma flotante por segundo)
Este rendimiento influye directamente en el tiempo de entrenamiento y de predicción de los modelos.
El lenguaje de programación, su compilador/intérprete y las librerías numéricas condicionan cómo se aprovechan CPU y GPU: número de cores utilizados, organización de tareas, gestión de memoria, etc.
[ ]:
clf.fit(x_train, y_train)
SVC(kernel='linear', random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(kernel='linear', random_state=0)
[ ]:
from time import perf_counter
t0 = perf_counter()
clf.fit(x_train, y_train)
t1 = perf_counter()
print("Tiempo de entrenamiento:", t1 - t0, "s")
t0 = perf_counter()
y_pred = clf.predict(x_test)
t1 = perf_counter()
print("Tiempo de predicción:", t1 - t0, "s")
Tiempo de entrenamiento: 0.48070470802485943 s
Tiempo de predicción: 0.11679345811717212 s
[ ]:
!uv add memory_profiler
Resolved 99 packages in 0.48ms
Audited 94 packages in 0.01ms
[ ]:
from memory_profiler import memory_usage
def train():
clf.fit(x_train, y_train)
return clf
mem_usage = memory_usage(train)
print("Memoria máxima (MB):", max(mem_usage))
Memoria máxima (MB): 242.875
La memoria no es un problema a priori que debe de preocuparos en este punto de vuestro aprendizaje. El tiempo de entrenamiento y predicción, sí.
![]() Isaac Lera and Gabriel Moya Universitat de les Illes Balears isaac.lera@uib.edu, gabriel.moya@uib.edu
Isaac Lera and Gabriel Moya Universitat de les Illes Balears isaac.lera@uib.edu, gabriel.moya@uib.edu
Anexo A
`One-Hot Encoding’ sería la técnica más idonea para transformar las categorías del dataset de mushrooms.
[5]:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import pandas as pd
df = pd.read_csv("data/mushrooms.csv")
# Por simplicidad, renombramos las columnas
es_col = [
"clase",
"forma del sombrero",
"superficie del sombrero",
"color del sombrero",
"magulladuras",
"olor",
"unión de las láminas",
"espaciamiento de las láminas",
"tamaño de las láminas",
"color de las láminas",
"forma del tallo",
"raíz del tallo",
"superficie del tallo por encima del anillo",
"superficie del tallo por debajo del anillo",
"color del tallo por encima del anillo",
"color del tallo por debajo del anillo",
"tipo de velo",
"color del velo",
"número de anillos",
"tipo de anillo",
"color de la impresión de esporas",
"población",
"hábitat"
]
df.columns = es_col
X = df.drop('población', axis=1)
y = df['población']
ct = ColumnTransformer(
transformers=[
('ohe', OneHotEncoder(handle_unknown='ignore'), X.columns)
],
remainder='drop'
)
X_encoded = ct.fit_transform(X)
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y, test_size=0.2, random_state=0
)
print(type(x_train)) # https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html
print("-"*100)
print(x_train.shape) # 113!
print("-"*100)
print(x_train[:3,:3])
print("-+"*50)
clf = SVC(C=1.0, kernel="linear", random_state=0)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print(classification_report(y_test, y_pred))
<class 'scipy.sparse._csr.csr_matrix'>
----------------------------------------------------------------------------------------------------
(6499, 113)
----------------------------------------------------------------------------------------------------
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 3 stored elements and shape (3, 3)>
Coords Values
(0, 0) 1.0
(1, 0) 1.0
(2, 0) 1.0
-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
precision recall f1-score support
a 0.44 0.58 0.50 65
c 0.68 0.87 0.76 62
n 0.36 0.19 0.25 93
s 0.43 0.63 0.51 237
v 0.77 0.59 0.67 827
y 0.45 0.56 0.50 341
accuracy 0.58 1625
macro avg 0.52 0.57 0.53 1625
weighted avg 0.62 0.58 0.59 1625
[ ]: